Son grandes polímeros formados por la repetición de monómeros denominados nucleótido, unidos mediante enlaces fosfodiéster. Se forman,
largas cadenas; algunas moléculas de ácidos nucleicos llegan a alcanzar tamaños
gigantescos, con millones de nucleótidos encadenados.
Importancia biológica de los ácidos nucleicos
Un
organismo vivo contiene un conjunto de
instrucciones para formar una réplica de sí mismo.
El genoma del organismo o material genético es donde está toda esa información.
Los genomas de todas las células están formados por ADN. Algunos genomas virales están formados por ARN.
En muchas bacterias, el genoma puede consistir en una solo molécula de ADN.
La información que especifica la estructura primaria de una proteína esta codificada en la secuencia de nucleótidos en el ADN.
Los ácidos nucleícos representan la cuarta gran clase de macromoléculas.
Estas al igual que las proteínas y los polisacáridos, contienen múltiples unidades manométricas similares que se unen en forma covalente para producir polímeros grandes.
El genoma del organismo o material genético es donde está toda esa información.
Los genomas de todas las células están formados por ADN. Algunos genomas virales están formados por ARN.
En muchas bacterias, el genoma puede consistir en una solo molécula de ADN.
La información que especifica la estructura primaria de una proteína esta codificada en la secuencia de nucleótidos en el ADN.
Los ácidos nucleícos representan la cuarta gran clase de macromoléculas.
Estas al igual que las proteínas y los polisacáridos, contienen múltiples unidades manométricas similares que se unen en forma covalente para producir polímeros grandes.
Funciones de los ácidos nucleícos
Duplicación
del ADN
Transcripción del ADN para formar ARNm y otros ARN
Traducción, en los ribosomas, del mensaje contenido en el ARNm a proteínas.
Expresión del mensaje genético, proteínas.
Transcripción del ADN para formar ARNm y otros ARN
Traducción, en los ribosomas, del mensaje contenido en el ARNm a proteínas.
Expresión del mensaje genético, proteínas.
En
1869, Friedrich Miescher descubre la sustancia que resulto ser acido
desoxirribonucleico (ADN). Acido desoxirribonucleico (ADN) está conformado por
carbono, hidrógeno, oxígeno y alto contenido de fósforo.
El nombre inicial de esta sustancia fue “nucleína”, luego se cambio a acido nucleíco.
Hoppe-Seyler aisló una sustancia muy parecida en las células de levadura, esta sustancia era ARN. 1944, Oswald Avery, Colin MacLeod y Maclyn McCarty demostraron que el ADN es la molécula que contiene la información genética. Por aquella época se conocía muy poco sobre la estructura de ADN.
carbono, hidrógeno, oxígeno y alto contenido de fósforo.
El nombre inicial de esta sustancia fue “nucleína”, luego se cambio a acido nucleíco.
Hoppe-Seyler aisló una sustancia muy parecida en las células de levadura, esta sustancia era ARN. 1944, Oswald Avery, Colin MacLeod y Maclyn McCarty demostraron que el ADN es la molécula que contiene la información genética. Por aquella época se conocía muy poco sobre la estructura de ADN.
Determinación de la estructura del ADN
 El 28 de
febrero de 1953 los científicos James Watson y Francis Crick determinan la estructura
del ADN. Los científicos propusieron
el modelo de la doble hélice de ADN para representar la estructura
tridimensional del polímero.
El 28 de
febrero de 1953 los científicos James Watson y Francis Crick determinan la estructura
del ADN. Los científicos propusieron
el modelo de la doble hélice de ADN para representar la estructura
tridimensional del polímero.En una serie de cinco artículos en el mismo número de Nature se publicó la evidencia experimental que apoyaba el modelo de Watson y Crick.
De éstos, el artículo de Franklin y Raymond Gosling fue la primera publicación con datos de difracción de rayos X que apoyaba el modelo de Watson y Crick, y en ese mismo número de Nature también aparecía un artículo sobre la estructura del ADN de Maurice Wilkins y sus colaboradores.
Watson, Crick y Wilkins recibieron conjuntamente, en 1962, después de la muerte de Rosalind Franklin, el Premio Nobel en Fisiología o Medicina. Sin embargo, el debate continúa sobre quién debería recibir crédito por el descubrimiento.
Niveles estructurales de los ácidos nucleicos

Estructura secundaria del ADN

Estructura
terciaria del ADN
superenrollamiento de la molécula

Estructura
cuaternaria del ADN
superenrollamiento de la molécula con otras moléculas

Los nucleótidos son los bloques de
construcción de los ácidos nucleicos
Los
ácidos nucleicos son polinucleótidos, o polímeros de nucleótidos. Los
nucleótidos tienen tres componentes: un azúcar de cinco carbono, uno o más
grupos fosfato y un compuesto nitrogenado débilmente básico llamado base. Las
bases que se encuentran en los nucleótidos son PIRIMIDINAS y PURINAS
sustituidas.
La pentosa
suele ser ribosa (D-ribofuranosa) o 2-desoxirribosa (2-desoxi-D-ribofuranosa).
Los N-glicósidos pirimidina o purina de estos azúcares se llaman nucleósidos.
Los nucleótidos son los ésteres de fosfato de los nucleósidos; los nucleótidos
comunes contienen uno a tres grupos fosforilo. Los nucleótidos que contienen
ribosa se llaman ribonucleótidos, y los que contienen desoxirribosa se llaman
desoxirribonucleótidos. A. Ribosa
y desoxirribosa:
Los azúcares componentes de los nucleótidos que se encuentran en
los ácidos nucleicos. Los dos azúcares aparecen como proyecciones de Haworth de
la configuración b de las formas de anillo de furanosa. Es la configuración
estable que existe en los nucleótidos y polinucleótidos. Cada uno de esos
anillos de furanosa puede adoptar conformaciones diferentes. La conformación de
la desoxirribosa predomina en el ADN de doble hebra.

B. Pirimidinas y purinas
Las bases que se encuentran en los nucleótidos son derivados de pirimidina o de purina.
Estructura de las purinas y pirimidinas
 La pirimidina tiene un solo anillo de cuatro átomos de carbono y dos de nitrógeno.
La pirimidina tiene un solo anillo de cuatro átomos de carbono y dos de nitrógeno.La purina tiene un sistema de anillos fundidos de pirimidina y de imidazol. Los dos tiposde bases son no saturados, con dobles enlaces conjugados. Esta propiedad hace que los anillos sean planos, y también explica su capacidad de absorber la luz ultravioleta.
Clasifiación
Las purinas y pirimidinas sustituidas son ubicuas en las células vivas, pero casi nunca se encuentran las bases no sustituidas en los sistemas biológicos. Las principales pirimidinas que hay en los nucleótidos son uracilo (2,4-dioxopirimidina, U), timina
(2,4-dioxo-5-metilpirimidina, T) y citosina (2-oxo-4-aminopirimidina, C). Las principales purinas son adenina (6-aminopurina, A) y guanina (2-amino-6-oxopurina, G). Las estructuras químicas de esas cinco bases principales la timina es una forma sustituida de uracilo, también se puede llamar 5-metiluracilo. La adenina, la guanina y la citosina están en ribonucleótidos y desoxirribonucleótidos. El uracilo se encuentra principalmente en ribonucleótidos y la timina en desoxirribonucleótidos.
(2,4-dioxo-5-metilpirimidina, T) y citosina (2-oxo-4-aminopirimidina, C). Las principales purinas son adenina (6-aminopurina, A) y guanina (2-amino-6-oxopurina, G). Las estructuras químicas de esas cinco bases principales la timina es una forma sustituida de uracilo, también se puede llamar 5-metiluracilo. La adenina, la guanina y la citosina están en ribonucleótidos y desoxirribonucleótidos. El uracilo se encuentra principalmente en ribonucleótidos y la timina en desoxirribonucleótidos.

Las purinas y las pirimidinas son bases débiles relativamente insolubles en agua al pH fisiológico.
Estructura de algunas nucleobases menos comunes
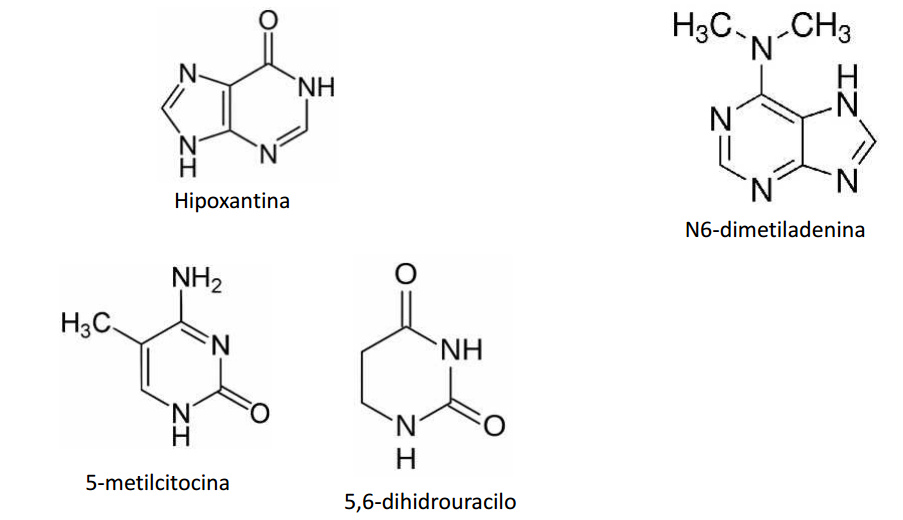
Sin embargo, dentro de las células la mayor parte de bases pirimidina y purina se encuentran como constituyentes de nucleótidos y polinucleótidos, compuestos que son muy hidrosolubles.
Cada base heterocíclica de los nucleótidos comunes puede existir cuando menos en dos formas tautómeras. La adenina y la citosina (que son amidinas cíclicas) pueden existir en sus formas amino o imino, y la guanina, timina y uracilo (que son amidas cíclicas) pueden existir en forma de lactama (ceto) o de lactima (enol). Las formas tautómeras de cada base existen en equilibrio, pero los tautómeros amino y lactama son más estables, y en consecuencia predominan bajo las condiciones que hay en el interior de la mayoría de las células. Los anillos permanecen no saturados y planos en cada tautómero.
Cada base heterocíclica de los nucleótidos comunes puede existir cuando menos en dos formas tautómeras. La adenina y la citosina (que son amidinas cíclicas) pueden existir en sus formas amino o imino, y la guanina, timina y uracilo (que son amidas cíclicas) pueden existir en forma de lactama (ceto) o de lactima (enol). Las formas tautómeras de cada base existen en equilibrio, pero los tautómeros amino y lactama son más estables, y en consecuencia predominan bajo las condiciones que hay en el interior de la mayoría de las células. Los anillos permanecen no saturados y planos en cada tautómero.
Estructuras de los tautómeros

C. Nucleósidos
Los nucleósidos están formados por ribosa y desoxirribosa y una base heterocíclica. En cada nucleósido, un enlace b-N-glicosídico conecta el C-1 del azúcar al N-1 de la pirimidina o al N-9 de la purina. Por consiguiente, los nucleósidos son derivados N-ribosilo o N-desoxirribosilo de las pirimidinas o las purinas. La convención de numeración para los átomos de carbono y nitrógeno de los nucleósidos refleja que están formados por una base y un azúcar de cinco carbonos, y cada uno de ellos tiene su propio esquema de numeración. La designación de los átomos en las partes de purina y pirimidina tiene preferencia. Por consiguiente, los átomos de las bases se numeran 1, 2, 3, etc., en tanto que los del anillo de furanosa se diferencian por tener primas (´ ). Así, el enlace b-N-glicosídico se une al átomo de C-1 , o 1 , de la parte del azúcar a la base. La ribosa y la desoxirribosa difieren en la posición del C-2 , o 2 .
Los nucleósidos están formados por ribosa y desoxirribosa y una base heterocíclica. En cada nucleósido, un enlace b-N-glicosídico conecta el C-1 del azúcar al N-1 de la pirimidina o al N-9 de la purina. Por consiguiente, los nucleósidos son derivados N-ribosilo o N-desoxirribosilo de las pirimidinas o las purinas. La convención de numeración para los átomos de carbono y nitrógeno de los nucleósidos refleja que están formados por una base y un azúcar de cinco carbonos, y cada uno de ellos tiene su propio esquema de numeración. La designación de los átomos en las partes de purina y pirimidina tiene preferencia. Por consiguiente, los átomos de las bases se numeran 1, 2, 3, etc., en tanto que los del anillo de furanosa se diferencian por tener primas (´ ). Así, el enlace b-N-glicosídico se une al átomo de C-1 , o 1 , de la parte del azúcar a la base. La ribosa y la desoxirribosa difieren en la posición del C-2 , o 2 .
 |
| Sitios para enlaces de hidrógeno en las bases de ácidos nucleicos. |
Estructura química de los nucleósidos
 |
| a. Ribonucleósidos y b. Desoxirribonucleósidos |
Conformación sin y anti Adenosina
Algunos nucleótidos toman la conformación sin o anti. En los nucleósidos comunes de pirimidinas predomina la conformación anti. En los ácidos nucleicos, que son polímeros de los nucleótidos, predomina las conformaciones anti.

D. Nucleótidos
Los nucleótidos son derivados fosforilados de los nucleósidos. Los ribonucleósidos contienen tres grupos hidroxilo que se pueden fosforilar (2 , 3 y 5 ), y los desoxirribonucleósidos contienen dos de esos grupos hidroxilo (3 y 5 ). En los nucleótidos naturales, los grupos fosforilo suelen estar unidos al átomo de oxígeno del grupo 5 -hidroxilo. Por convención, siempre se supone que un nucleótido es un éster de 5 -fosfato, a menos que se indique otra cosa.
Los nucleótidos son derivados fosforilados de los nucleósidos. Los ribonucleósidos contienen tres grupos hidroxilo que se pueden fosforilar (2 , 3 y 5 ), y los desoxirribonucleósidos contienen dos de esos grupos hidroxilo (3 y 5 ). En los nucleótidos naturales, los grupos fosforilo suelen estar unidos al átomo de oxígeno del grupo 5 -hidroxilo. Por convención, siempre se supone que un nucleótido es un éster de 5 -fosfato, a menos que se indique otra cosa.
Estructura química de los desoxirribonucleotido-5’-monofosfatos


Características del ADN
El ADN tiene doble hebra
1950, el ADN es un polímero lineal de residuos de 2’ desoxirribonucleotido unidos por 3’,5’-fosfodiester.Erwin Chargaff había deducido ciertas regularidades en las composiciones de nucleótidos de muestras de ADN obtenidas de gran variedad de procariotas y eucariotas. Entre otras cosas, Chargaff observó que en el ADN de determinada célula están presentes A y T en cantidades equimolares, así como G y C.
El modelo de ADN propuesto por Watson y Crick en 1953 se basó en las estructuras conocidas de los nucleósidos, sobre figuras de difracción de rayos X que obtuvieron Rosalind Franklin y Maurice Wilkins de fibras de ADN, y en las equivalencias químicas notadas por Chargaff. El modelo de Watson-Crick explicó las cantidades iguales de purinas y pirimidinas al sugerir que el ADN tiene doble hebra (doble cadena) y que las bases en una hebra se apareaban en forma específica con las bases de la otra: A con T y G con C. La estructura propuesta por Watson y Crick se llama hoy conformación B del ADN, o simplemente B-ADN.
Es importante apreciar la estructura del ADN para comprender los procesos de su replicación y transcripción. El ADN es el almacén de la información biológica.Cada célula contiene docenas de enzimas y proteínas que se unen al ADN y reconocen ciertas propiedades estructurales, como la secuencia de nucleótidos.
Doble hebra de ADN
A. Unión de nucleótidos por enlaces de 3’,5’ fosfodiester.
B. Formación de una doble hélice con dos hebras antiparalelas.
C. Estabilización de la doble hélice por fuerzas débiles.
D.Conformación de ADN de doble hebra
A. Unión de nucleótidos por enlaces de 3’,5’ fosfodiester.
B. Formación de una doble hélice con dos hebras antiparalelas.
C. Estabilización de la doble hélice por fuerzas débiles.
D.Conformación de ADN de doble hebra
A. Unión de nucleótidos por enlaces de 3’,5’ fosfodiester.
La estructura primaria de una proteína se refiere a la secuencia de sus residuos de aminoácido unidos por enlaces peptídicos; en forma parecida, la estructura primaria de un ácido nucleico es la secuencia de sus residuos de nucleótido unidos por enlaces 3 ,5 -fosfodiéster. Un tetranucleótido tiene Estructura química:pdApdGpdTpdC. Los residuos de nucleótido están unidos por enlaces 3’-5’-fosfodiester.El nucleótido con un grupo 5’-fosforilo libre se llama extremo 5’, y el nucleótido con un grupo 3’-hidroxilo libre se llama extremo 3’.


B. Formación de una doble hélice con dos hebras antiparalelas.
La mayor parte de las moléculas de ADN consisten en dos hebras, de polinucleótidos. Cada una de las bases en una hebra forma puentes de hidrógeno con una base de la hebra opuesta.Los pares de bases mas comunes están entre los tautómeros lactoma y amino de las bases.

La molécula de ADN se puede visualizar como una “escalera” que se ha torcido para formar una hélice. Las bases apareadas representan los peldaños de la escalera, y los esqueletos de azúcar-fosfato representan los soportes. Cada hebra complementaria sirve como una plantilla perfecta a la otra. Esta complementariedad es responsable de la regularidad general de la estructura del ADN de doble hebra. Sin embargo, el apareamiento de bases complementarias solo no produce una hélice. En el B-ADN, los pares de bases se apilan uno sobre otro, y son casi perpendiculares al eje longitudinal de la molécula. Las interacciones no covalentes cooperativas entre las superficies superior e inferior de cada par de base acercan entre sí a esos pares y crean un interior hidrofóbico que hace que se tuerza el esqueleto de azúcar-fosfato.

La doble hélice tiene dos surcos de ancho desigual, por la forma en que se apilan los pares de bases y en que se tuercen los esqueletos de azúcar-fosfato. Esos surcos se llaman surco mayor y surco menor. Dentro de cada surco, los grupos funcionales en las orillas de los pares de bases quedan expuestos al agua. Cada par de bases tiene una pauta distintiva de grupos químicos en los surcos. Como los pares de bases son accesibles en los surcos, las moléculas que interactúan con determinados pares de bases pueden identificarlos sin alterar la hélice. Esto tiene importancia particular en las proteínas que deben unirse al ADN de doble hebra y “leer” determinada secuencia. El B-ADN es una hélice derecha con 2.37 nm de diámetro. El ascenso de la hélice es la distancia entre un par de bases y el siguiente, a lo largo del eje de la hélice, y es de 0.33 nm en promedio; el paso de la hélice es la distancia para completar una vuelta, aproximadamente 3.40 nm. Esos valores varían dentro de ciertos límites que dependen de la composición en bases. Ya que hay unos 10.4 pares de bases por vuelta de la hélice, el ángulo de rotación entre nucleótidos adyacentes en cada hebra es de unos 34.6° (360/10.4).

La longitud de las moléculas de ADN de doble hebra se expresa con frecuencia en términos de pares de bases (pb). Por comodidad, las estructuras más largas se miden en miles de pares de bases o kilopares de bases, que se abrevian kb. La mayor parte de los genomas bacterianos consisten en una sola molécula de ADN de varios miles de kb; por ejemplo, el cromosoma de Escherichia coli tiene 4 600 kb. Las moléculas más grandes de ADN en los cromosomas de mamíferos y plantas de floración pueden ser de varios cientos de miles de kb de longitud. El genoma humano contiene 3 200 000 kb (3.2 109 pares de bases) de ADN.
 |
| a) Modelo de bolas y palillos. Los pares de bases son casi perpendiculares a las columnas vertebrales de azúcar-fosfato.b) Modelo de relleno espacial. Clave de colores: carbono gris, nitrógeno azul, oxígeno rojo, fósforo púrpura. |
C. Estabilización de la doble hélice por fuerzas débiles.
Las fuerzas que mantienen las conformaciones nativas de las estructuras celulares complejas tienen la fuerza suficiente para mantener las estructuras, pero la debilidad suficiente para permitir que haya flexibilidad de conformación. Los enlaces covalentes
entre los residuos adyacentes determinan las formas tridimensionales de esas macromoléculas. Hay cuatro clases de interacciones que afectan la conformación del ADN de doble hebra:
1. Interacciones de apilamiento: Los pares de bases apilados forman contactos de van der Waals. Aunque las fuerzas entre los pares de bases individuales apilados son débiles, son aditivas, por lo que en las moléculas grandes de ADN los contactos de van der Waals son una fuente importante de estabilidad.
2. Puentes de hidrógeno: Los puentes de hidrógeno entre pares de bases forman una importante fuerza estabilizadora.
3. Efectos hidrofóbicos: Al sepultar los anillos hidrofóbicos de purina y pirimidina en el interior de la doble hélice aumenta la estabilidad de la hélice.
4. Interacciones entre cargas: La repulsión electrostática de los grupos fosfato con carga negativa en el esqueleto es una fuente potencial de inestabilidad de la hélice de ADN. Sin embargo, la repulsión se minimiza por la presencia de cationes como y proteínas catiónicas (que contienen abundancia de los residuos básicos arginina y lisina).
entre los residuos adyacentes determinan las formas tridimensionales de esas macromoléculas. Hay cuatro clases de interacciones que afectan la conformación del ADN de doble hebra:
1. Interacciones de apilamiento: Los pares de bases apilados forman contactos de van der Waals. Aunque las fuerzas entre los pares de bases individuales apilados son débiles, son aditivas, por lo que en las moléculas grandes de ADN los contactos de van der Waals son una fuente importante de estabilidad.
2. Puentes de hidrógeno: Los puentes de hidrógeno entre pares de bases forman una importante fuerza estabilizadora.
3. Efectos hidrofóbicos: Al sepultar los anillos hidrofóbicos de purina y pirimidina en el interior de la doble hélice aumenta la estabilidad de la hélice.
4. Interacciones entre cargas: La repulsión electrostática de los grupos fosfato con carga negativa en el esqueleto es una fuente potencial de inestabilidad de la hélice de ADN. Sin embargo, la repulsión se minimiza por la presencia de cationes como y proteínas catiónicas (que contienen abundancia de los residuos básicos arginina y lisina).
 El ADN de doble hebra es termodinámicamente más estable que las hebras separadas, lo cual explica por qué predomina la forma de doblehebra in vivo. Sin embargo, a veces se puede alterar la estructura de regiones localizadas de la doble hélice al desenrollarse. Esa alteración sucede durante la replicación, reparación, recombinación y transcripción del ADN. Al desenrollamiento y la separación completos de las hebras individuales complementarias se le llama desnaturalización.La desnaturalización sólo sucede in vitro. El ADN de doble hebra se puede desnaturalizar con calor o con un agente
El ADN de doble hebra es termodinámicamente más estable que las hebras separadas, lo cual explica por qué predomina la forma de doblehebra in vivo. Sin embargo, a veces se puede alterar la estructura de regiones localizadas de la doble hélice al desenrollarse. Esa alteración sucede durante la replicación, reparación, recombinación y transcripción del ADN. Al desenrollamiento y la separación completos de las hebras individuales complementarias se le llama desnaturalización.La desnaturalización sólo sucede in vitro. El ADN de doble hebra se puede desnaturalizar con calor o con un agentecaotrópico, como urea o cloruro de guanidinio. En estudios de desnaturalización térmica se aumenta lentamente la temperatura de una solución de ADN. Al elevar la temperatura, se dispersan cada vez más bases y se rompen más puentes de hidrógeno entre pares de bases. Llega un momento en que las dos cadenas se separan por completo. La temperatura a la que la mitad del ADN se ha convertido en una sola cadena se le llama punto de fusión, Tm.
Para medir el grado de desnaturalización se usa la absorción de luz ultravioleta. Se hacen mediciones a una longitud de onda de 260 nm, cercana al máximo de absorbencia para los ácidos nucleicos. El ADN de una hebra absorbe 12 a 14% más luz que el ADN de doble hebra a 260 nm. Una gráfica del cambio de absorbencia de una solución de ADN en función de la temperatura se llama curva de fusión. La absorbencia aumenta en forma marcada en el punto de fusión, y la transición de ADN de doble hebra a una hebra se efectúa dentro de límites estrechos de temperatura.
 |
| curva de fusión |
El ADN de doble hebra puede asumir distintas conformaciones bajo condiciones diferentes. La conformación local también se afecta por dobleces en la molécula de ADN, y de si está unida a una proteína. El resultado es que la cantidad de pares de bases por
vuelta en el B-ADN puede fluctuar de 10.2 a 10.6.Además de varias formas de B-ADN, hay dos conformaciones muy diferentes del ADN. Se forma A-ADN cuando se deshidrata el ADN, y se puede formar Z-ADN cuando están presentes ciertas secuencias. (Las formas A y B de ADN fueron descubiertas por Rosalind Franklin en 1952). El A-ADN está enrollado más apretadamente que el B-ADN, y los surcos mayor y menor del A-ADN tienen ancho similar. Hay unos 11 pb por vuelta en el A-ADN, y los pares de bases están desplazados unos 20° en relación al eje mayor de la hélice. El Z-ADN difiere todavía más del B-ADN. En el ZADN no hay surcos y la hélice es izquierda, no derecha. La conformación Z-ADN está en regiones ricas en G/C. Los residuos de desoxiguanilato en el Z-ADN tienen distinta conformación de azúcares (3 -endo) y la base tiene la conformación sin. Tanto las conformaciones A-ADN como Z-ADN existen in vivo, pero se confinan a cortas regiones del ADN.
Superenrollamiento del ADN
 Una molécula circular de ADN con la conformación B tiene un promedio de 10.4 pares de bases por vuelta. Se dice que está relajada si tal molécula puede reposar plana sobre una superficie. Esta doble hélice relajada se puede seguir envolviendo o desenvolviendo si se rompen las hebras del ADN y se tuercen los dos extremos de la molécula lineal en direcciones opuestas. Cuando se vuelven a unir las hebras para crear un círculo, ya no hay 10.4 pares de bases por vuelta, las necesarias para mantener la conformación B estable. La molécula circular se compensa por el envolvimiento o desenvolvimiento formando superenrollamientos que restauran 10.4 pares de bases por vuelta de la doble hélice. Cada superenrollamiento se compensa por una vuelta de la doble hélice.
Una molécula circular de ADN con la conformación B tiene un promedio de 10.4 pares de bases por vuelta. Se dice que está relajada si tal molécula puede reposar plana sobre una superficie. Esta doble hélice relajada se puede seguir envolviendo o desenvolviendo si se rompen las hebras del ADN y se tuercen los dos extremos de la molécula lineal en direcciones opuestas. Cuando se vuelven a unir las hebras para crear un círculo, ya no hay 10.4 pares de bases por vuelta, las necesarias para mantener la conformación B estable. La molécula circular se compensa por el envolvimiento o desenvolvimiento formando superenrollamientos que restauran 10.4 pares de bases por vuelta de la doble hélice. Cada superenrollamiento se compensa por una vuelta de la doble hélice. |
| Topoisomerasas I humana |
La información contenida en el genoma debe especificar la estructura primarias de cada proteína en un organismo.
- Gen: secuencia de ADN que se transcribe a ARN. Esta definición también engloba los genes que no codifican proteínas.
- Genes domésticos: que codifican proteínas o moléculas de ARN que son esenciales para las actividades en todas las células vivas, (Ej. Enzimas que intervienen en procesos metabólicos).
- Genes especiales: que solo se transcriben en circunstancias especiales, (Ej. Durante la división celular) o genes que solo se expresen en un cierto tipo de células (Ej. la insulina solo se produce en las células pancreáticas).
- La cantidad de genes van desde 15 000 en Drosophila melanogaster a mas de 50 000 en mamíferos.
Diversos tipos de ARN en las células
Las moléculas de ARN participan en varios procesos asociados a la expresión génica. Esas moléculas se encuentran en copias múltiples y en varias formas distintas dentro de una célula dada. Hay cuatro clases principales de ARN en todas las células vivas:1. ARN ribosómico (ARNr): moléculas que son parte integral de los ribosomas (ribonucleoproteínas intracelulares que son sitios de síntesis de proteínas). El ARNribosómico es la clase más abundante de ácido ribonucleico, que forma 80% delARN celular total.
2. ARN de transferencia (ARNt): son moléculas que llevan a los aminoácidos activados a los ribosomas para su incorporación a las cadenas de péptidos en crecimiento durante la síntesis de proteínas. Las moléculas de ARNt sólo tienen de 73 a 95 residuos de nucleótidos de longitud. Forman un 15% del ARN celular total.
3. ARN mensajero(ARNm): moléculas que codifican las secuencias de aminoácidos en las proteínas. Son los “mensajeros” que llevan la información del ADN al complejo de traducción, donde se sintetizan las proteínas. En general, el ARNm sólo forma el 3% del ARN celular total. Estas moléculas son las menos estables de los ácidos ribonucleicos celulares.
4. ARN pequeño: moléculas presentes en todas las células. Algunas moléculas pequeñas de ARN tienen actividad catalítica o contribuyen a la actividad catalítica, asociadas a proteínas. Muchas de esas moléculas de ARN se relacionan con eventos de procesamiento que modifican al ARN después de que se ha sintetizado.
Las moléculas de ARN participan en varios procesos asociados a la expresión génica. Esas moléculas se encuentran en copias múltiples y en varias formas distintas dentro de una célula dada. Hay cuatro clases principales de ARN en todas las células vivas:1. ARN ribosómico (ARNr): moléculas que son parte integral de los ribosomas (ribonucleoproteínas intracelulares que son sitios de síntesis de proteínas). El ARNribosómico es la clase más abundante de ácido ribonucleico, que forma 80% delARN celular total.
2. ARN de transferencia (ARNt): son moléculas que llevan a los aminoácidos activados a los ribosomas para su incorporación a las cadenas de péptidos en crecimiento durante la síntesis de proteínas. Las moléculas de ARNt sólo tienen de 73 a 95 residuos de nucleótidos de longitud. Forman un 15% del ARN celular total.
3. ARN mensajero(ARNm): moléculas que codifican las secuencias de aminoácidos en las proteínas. Son los “mensajeros” que llevan la información del ADN al complejo de traducción, donde se sintetizan las proteínas. En general, el ARNm sólo forma el 3% del ARN celular total. Estas moléculas son las menos estables de los ácidos ribonucleicos celulares.
4. ARN pequeño: moléculas presentes en todas las células. Algunas moléculas pequeñas de ARN tienen actividad catalítica o contribuyen a la actividad catalítica, asociadas a proteínas. Muchas de esas moléculas de ARN se relacionan con eventos de procesamiento que modifican al ARN después de que se ha sintetizado.
ARN polimerasa
La ARN polimerasa es una ARN nucleotidiltransferasa. Su función es llevar a cabo la transcripción. Realiza una copia de ADN a ARN catalizando la formación de los enlaces fosfodiester entre ribonucleótidos. La copia la hace nucleótido a nucleótido, usando ribonucleósidos trifosfato (rNTP). En el ARN el ribonucleótido uracilo sustituye a la timina del ADN.La ARN polimerasa en general es oligomérica, estructurándose en un complejo formado por varias subunidades. Las subunidades comunes más grandes son dos: la β, que funciona como centro activo; y la β', que es la subunidad de unión al ADN. Está formado por una larga cola de 52 repeticiones del heptapéptido “YSPTSPS” con residuos fosforilables. El resto de subunidades de la ARN polimerasa son más pequeñas y participan en la unión a todos las proteínas que intervienen en la transcripción.
Las principales ARN polimerasas de eucariotas son la I, la II, la III, y la mitocondrial
Las principales ARN polimerasas de eucariotas son la I, la II, la III, y la mitocondrial
Los diferentes tipos de ARN polimerasas se diferencian en su composición de
aminoácidos, en su estructura, en su localización, en el tipo de ARN que
transcriben y en su forma de inhibición.
ARN polimerasa I: síntesis, reparación y revisión. Sintetiza precursores de ARN ribosómico.
ARN polimerasa II: reparación, sintetiza precursores de ARN mensajero, microARN y otros tipos de ácido ribonucleico. Esta polimerasa es el tipo más estudiado, y se requieren factores de transcripción para que se una a los promotores del ADN.
ARN polimerasa III: sintetiza ARN de transferencia, ARN ribosómico de 5S y otros pequeños ARN (ARNpequeños) encontrados en el núcleo celular (ARNp nucleares) y en el citoplasma (ARNp citoplasmáticos).
Otros tipos de ARN polimerasa se encuentran en la mitocondria y en cloroplasto
y en el núcleo del ribosoma.
aminoácidos, en su estructura, en su localización, en el tipo de ARN que
transcriben y en su forma de inhibición.
ARN polimerasa I: síntesis, reparación y revisión. Sintetiza precursores de ARN ribosómico.
ARN polimerasa II: reparación, sintetiza precursores de ARN mensajero, microARN y otros tipos de ácido ribonucleico. Esta polimerasa es el tipo más estudiado, y se requieren factores de transcripción para que se una a los promotores del ADN.
ARN polimerasa III: sintetiza ARN de transferencia, ARN ribosómico de 5S y otros pequeños ARN (ARNpequeños) encontrados en el núcleo celular (ARNp nucleares) y en el citoplasma (ARNp citoplasmáticos).
Otros tipos de ARN polimerasa se encuentran en la mitocondria y en cloroplasto
y en el núcleo del ribosoma.
Reacción catalizada por la ARN polimerasa
Cuando un ribonucleosido trifosfato entrante se aparea en forma correcta con el siguiente nucleótido no se aparea en la hebra de plantilla de ADN, la ARN polimerasa cataliza un ataque nucleofilico del grupo 3’-hidroxilo de la hebra creciente de ARN, al átomo de fosforo α- del ribonucleosido trifosfato entrante. El resultado es que se forma un fosfodiester y se libera un pirofosfato. La hidrolisis siguiente del pirofosfato catalizada por la pirofosfatasa suministra una fuerza impulsora termodinámica adicional para la reacción.
Cuando un ribonucleosido trifosfato entrante se aparea en forma correcta con el siguiente nucleótido no se aparea en la hebra de plantilla de ADN, la ARN polimerasa cataliza un ataque nucleofilico del grupo 3’-hidroxilo de la hebra creciente de ARN, al átomo de fosforo α- del ribonucleosido trifosfato entrante. El resultado es que se forma un fosfodiester y se libera un pirofosfato. La hidrolisis siguiente del pirofosfato catalizada por la pirofosfatasa suministra una fuerza impulsora termodinámica adicional para la reacción.
Comentarios de los vídeos:
Replicación del ADN: en este vídeo se presenta el proceso de replicación de ADN, en la cual mecanismo que permite al ADN duplicarse (es decir, sintetizar una copia idéntica). De esta manera de una molécula de ADN única, se obtienen dos o más "réplicas" de la primera.Esta duplicación del material genético se produce de acuerdo con un mecanismo semiconservador,lo que indica que los dos polímeros complementarias del ADN original, al separarse, sirven de molde cada una para la síntesis de una nueva cadena complementaria de la cadena molde, de forma que cada nueva doble hélice contiene una de las cadenas del ADN original. La molécula de ADN se abre como una cremallera por ruptura de los puentes de hidrógeno entre las bases complementarias puntos determinados: los orígenes de replicación. Las proteínas iniciadoras reconocen secuencias de nucleótidos específicas en esos puntos y facilitan la fijación de otras proteínas que permitirán la separación de las dos hebras de ADN formándose una horquilla de replicación. Un gran número de enzimas y proteínas intervienen en el mecanismo molecular de la replicación, formando el llamado complejo de replicación
Transcripción de ADN A ARN: La transcripción del ADN es el primer proceso de la expresión génica, mediante el cual se transfiere la información contenida en la secuencia del ADN hacia la secuencia de proteína utilizando diversos ARN como intermediarios. Durante la transcripción genética, las secuencias de ADN son copiadas a ARN mediante una enzima llamada ARN polimerasa que sintetiza un ARN mensajero que mantiene la información de la secuencia del ADN. De esta manera, la transcripción del ADN también podría llamarse síntesis del ARN mensajero.
Traducción (de ADN A proteína): La traducción es el segundo proceso de la síntesis proteica (parte del proceso general de la expresión génica). La traducción ocurre tanto en el citoplasma, donde se encuentran los ribosomas, como también en el retículo endoplasmático rugoso (RER). Los ribosomas están formados por una subunidad pequeña y una grande que rodean al ARN. En la traducción, el ARN mensajero se decodifica para producir un polipéptido específico de acuerdo con las reglas especificadas por el código genético. Es el proceso que convierte una secuencia de ARN mensajero en una cadena de aminoácidos para formar una proteína. Es necesario que la traducción venga precedida de un proceso de transcripción. El proceso de traducción tiene tres fases: iniciación, elongación y terminación (entre todos describen el crecimiento de la cadena de aminoácidos, o polipéptido, que es el producto de la traducción).
Medicamentos que
contienen Ácidos nucleíco
Abacavir
Es un fármaco
sintético análogo de los nucleósidos, inhibidor de la transcriptasa
inversa, que es utilizado en el tratamiento contra el VIH, causante
del sida. Existe una marca comercial que se expende en combinación con
otros fármacos antivirales (abacavir, zidovudina y lamivudina). Fue
aprobado para uso público en 1998.

Indicaciones
 El fármaco es usado para tratar el HIV
tipo 1 y debe siempre ser utilizado en combinación con otros agentes
antirretrovirales. Abacavir jamás debe usarse como único fármaco cuando se
cambien los regímenes antirretrovirales debido a pérdida de la respuesta viral.
El fármaco es usado para tratar el HIV
tipo 1 y debe siempre ser utilizado en combinación con otros agentes
antirretrovirales. Abacavir jamás debe usarse como único fármaco cuando se
cambien los regímenes antirretrovirales debido a pérdida de la respuesta viral.
Mecanismo de acción
El abacavir
es un análogo de la guanosina (una purina). Su objetivo es la
inhibición de la enzima transcriptasa
inversa.
Dosis
Las
propiedades farmacocinéticas del abacavir han sido estudiadas en pacientes
adultos asintomáticos infectados de HIV después de una dosis única i.v. de 150
mg y de dosis orales múltiples. Las constantes farmacocinéticas del abacavir
fueron independientes de la dosis entre 300 y 1200 mg/día.
Nevirapina:
 La nevirapina
(BI-RG-587) es un inhibidor de la transcriptasa inversa no nucleósido (INNTI)
con actividad frente al VIH-1. Estructuralmente es un miembro del grupo de las
dipiridodiazepinonas (C15H14N4O; PM 266.3). La nevirapina actúa por un
mecanismo de inhibición no competitiva reversible (1). Se une directamente a la
trascriptasa inversa (TI) causando una alteración del lugar catalítico del
enzima (2) y bloqueando las actividades de la ADN polimerasa, ARN-dependientes
y ADN-dependientes.
La nevirapina
(BI-RG-587) es un inhibidor de la transcriptasa inversa no nucleósido (INNTI)
con actividad frente al VIH-1. Estructuralmente es un miembro del grupo de las
dipiridodiazepinonas (C15H14N4O; PM 266.3). La nevirapina actúa por un
mecanismo de inhibición no competitiva reversible (1). Se une directamente a la
trascriptasa inversa (TI) causando una alteración del lugar catalítico del
enzima (2) y bloqueando las actividades de la ADN polimerasa, ARN-dependientes
y ADN-dependientes. Dosis:
Dosis:
Dosis
adulto: 200 mg/día durante 14 días, aumentando posteriormente a 200 mg/12
h oral, con o sin comida (esta pauta de inicio ha reducido la incidencia de
exantema).
Dosis
niño: 120 mg/m2/24 h durante 28 días, seguido de 200 mg/m2/12 h en niños
<9 años y de 120 mg/m2/12 h en niños >9 años.
Aciclovir

Es un fármaco antiviral que se usa en el tratamiento de las
infecciones producidas por la varicela,
el virus herpes humano (VHH), entre las que se incluyen el herpes bucal, el herpes zóster y la mononucleosis
infecciosa.
Este fármaco impide la replicación viral disminuyendo la extensión y duración
de la enfermedad.
Vías de
administración
El aciclovir se usa
principalmente por vía oral mediante formulaciones en comprimidos
y suspensión para el uso pediátrico. También se administra por vía tópica, en crema, e intravenoso en pacientes con infecciones graves
por herpes virus.
Mecanismo de
Acción
En su forma absorbible, el
aciclovir tiene poca afinidad a las enzimas de células no infectadas. Es
convertido selectivamente en una forma monofosfatada por una timidina quinasa que poseen los virus sensibles al medicamento.
Subsecuentemente, el monofosfato es fosforilado para ser convertido, primero en
difosfato - aciclo-GDP - y luego en el trifosfato activo - aciclo GTP, por quinasas celulares.
 El aciclo-GTP inhibe la síntesis
de ADN viral a través de un mecanismo competitivo con la polimerasa viral, y al ser
incorporada en la cadena de ADN en síntesis, detiene su replicación. Su
poca afinidad a las polimerasas celulares, sumado al hecho de que la fosforilación ocurre sólo en células infectadas,
hace que tenga una toxicidad baja.
El aciclo-GTP inhibe la síntesis
de ADN viral a través de un mecanismo competitivo con la polimerasa viral, y al ser
incorporada en la cadena de ADN en síntesis, detiene su replicación. Su
poca afinidad a las polimerasas celulares, sumado al hecho de que la fosforilación ocurre sólo en células infectadas,
hace que tenga una toxicidad baja.
Dosis
Para adultos y niños mayores de
12 años, la vía de administración es la infusión
intravenosa de 5 mg/kg de peso
cada 8 h, durante cinco días. La solución se preparara como indica el fabricante
y debe administrarse lentamente durante por lo menos 1 h. Para el herpes simple
y herpes zóster diseminado, se administra como se indica durante siete días. La
vía de administración oral es de 200 mg cinco veces al día, a intervalos de 4
h, durante cinco o más días.
Para Niños (menores de 12
años), la infusión intravenosa es de 250 mg/m2 de superficie corporal cada 8 h,
durante cinco días. Para el herpes simple, se administra durante siete días. El
medicamento está prescrito de preferencia por especialistas en casos graves y
en pacientes hospitalizados. En varicela se administran 20 mg/kg/día sin pasar
de 800 mg en 24 h durante por 5 días.